How to improve a predictive model?
How to improve a predictive model?
Don't waste good data.
In addition to perspectives of cognitive architecture, I will post information about human and machine learning.
For example, I benefited from Amy Hodler’s short presentation “Hate Wasting Good Data? Reclaim Predictive Information with Knowledge Graphs”:
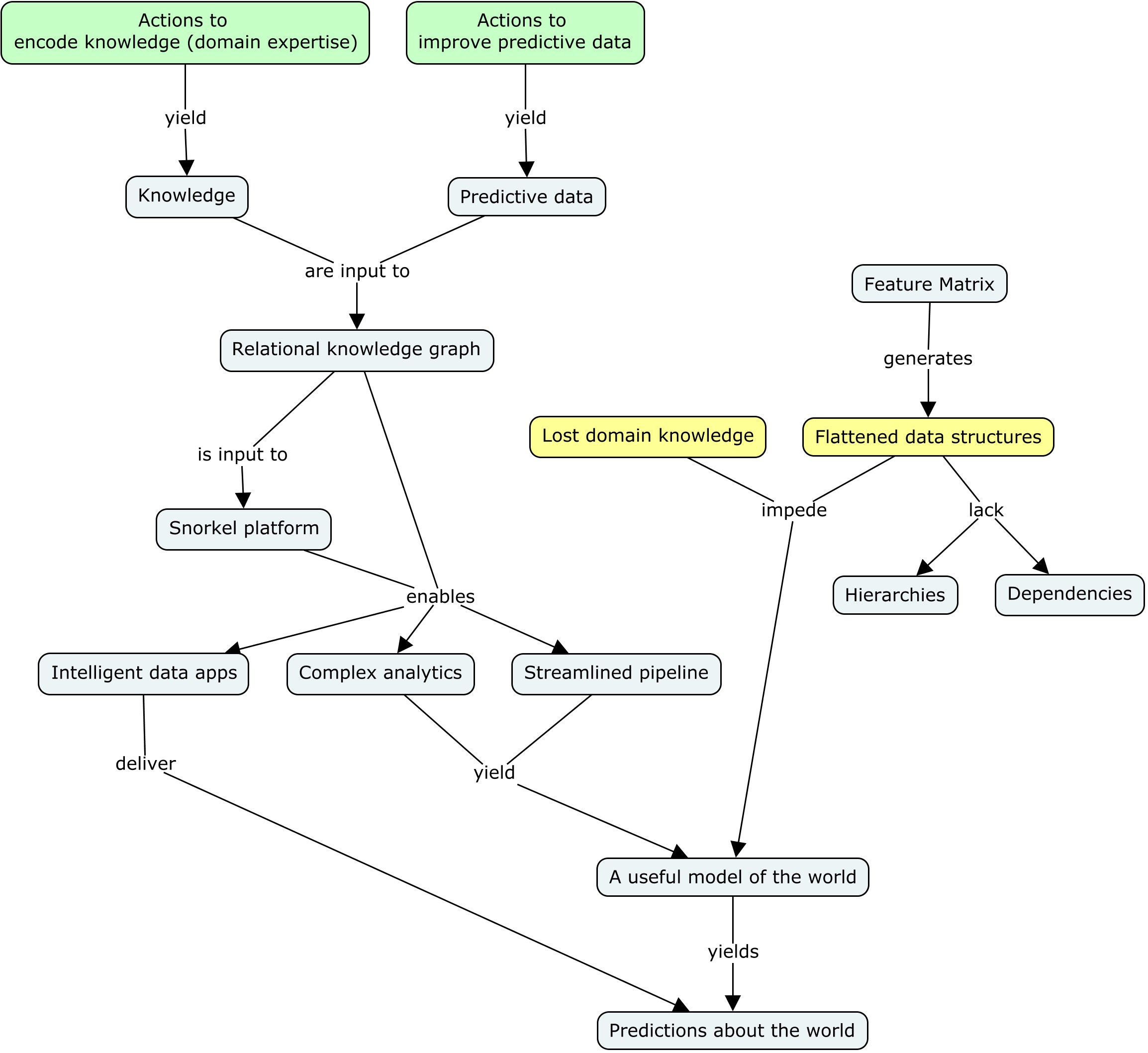
Here’s my two-part interpretation as a process hierarchy and a graph.
Process hierarchy
Actions:
Improve predictive data
Decide what to add
Add more data
Add higher-quality data
Add richer/varied data
Identify sources of corporate data
Capture business logic
Select ML techniques to apply to relationally-organized data
Apply graph feature engineering
Enhance data variety and contextual information
Encode knowledge (domain expertise)
Select a method to encode knowledge
Clean and preprocess data
Augment data
Sample data
Conduct feature engineering
Manually label
Conduct weak supervision and programmatic labeling
Apply generative models and synthetic data generation
Improve model architecture
Apply loss function
Add a semantic map with layers
Select sources
BI tools
Notebooks
ML feature engineering
Data apps
Map business meanings to data
Feed predictive data and knowledge to a platform (like Snorkel)
Produce a relational knowledge graph
Model the business concepts, relationships, and associated logic
Add heuristics
Add business rules
Add semantic organization
Create intelligent data apps
Run complex analytics
Apply graph analytics
Achieve reasoning
Apply machine learning
Achieve knowledge sharing
Graph
Goals:
Represent a useful model of the world
Make predictions about the world
Issues:
Flattened data structures
Relationships, including hierarchies and dependencies, are flattened in a Feature Matrix.
Lost domain knowledge